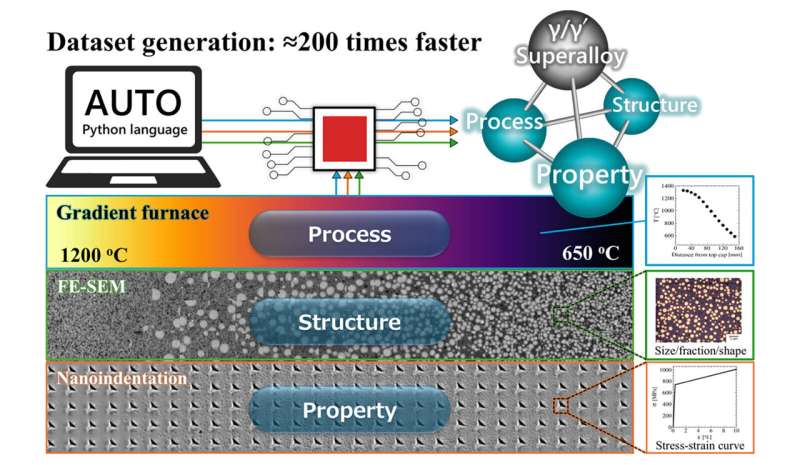
A research team at the National Institute for Materials Science (NIMS) has unveiled a groundbreaking automated high-throughput system designed to generate extensive datasets from a single sample of a superalloy used in aircraft engines. This innovative system produced an impressive experimental dataset containing thousands of records in just 13 days, a process that traditionally takes over seven years.
The datasets include crucial information, such as interconnected processing conditions, microstructural features, and yield strengths, collectively referred to as Process–Structure–Property datasets. This rapid data generation is over 200 times faster than conventional methods, which could significantly enhance data-driven materials design, according to the research published in the journal Materials & Design.
High-precision experimental data plays a vital role in understanding material mechanisms and developing new materials. It is essential for formulating theories, constructing models, conducting numerical simulations, and applying machine learning techniques. The ability to generate large quantities of accurate Process–Structure–Property datasets is particularly vital for optimizing the processing methods of heat-resistant superalloys, which have complex, multi-element microstructures.
Traditionally, creating such comprehensive databases requires extensive experimental work and considerable resources, often hindering the advancement of high-performance superalloys. The NIMS team has addressed this challenge by developing an automated high-throughput evaluation system capable of generating these datasets from a single sample of a Ni-Co-based superalloy, specifically engineered for use in aircraft engine turbine disks.
The research team employed a gradient temperature furnace to thermally treat the superalloy sample, which allowed them to map a wide range of processing temperatures. Using an automatically controlled scanning electron microscope and a nanoindenter, they measured precipitate parameters and yield stress at various coordinates along the temperature gradient.
In just 13 days, the system produced a volume of Process–Structure–Property data that would have taken conventional methods approximately seven years and three months to achieve. This efficiency marks a significant leap forward in materials research.
Moving forward, the NIMS team plans to apply this automated system to construct databases for various target superalloys and develop new technologies for acquiring high-temperature yield stress and creep data. Additionally, they aim to formulate multi-component phase diagrams, which are essential for materials design, based on the constructed superalloy databases.
The ultimate goal is to use these advancements to create new heat-resistant superalloys that contribute to achieving carbon neutrality. As the demand for innovative materials grows, this automated high-throughput system could play a crucial role in shaping the future of materials science.
For further details, refer to the study by Thomas Hoefler et al, titled “Automated system for high-throughput process-structure-property dataset generation of structural materials: A γ/γ′ superalloy case study,” published in Materials & Design on November 11, 2025.